高性能视频播放调度系统
By 汤力嘉@秒拍
摘要:本文介绍了调度系统于视频播放中的作用,介绍常用的ip库使用以及优缺点,本文提出一种新的思路,用于实现高性能的视频播放调度。
简介
调度系统
传统的调度系统主要应用于应急指挥所、值班室、急救中心、矿井、应急车等。本文所指的调度系统是网络上使用的调度系统,所有用户的请求,会先请求网络中固定的调度系统模块,调度系统根据一些规则,选择不同的后端服务器进行服务,调度系统起到负载均衡、隔离故障、健康检查、日志记录、权限分配等集中逻辑,因此调度系统的高可用、高吞吐量、高性能显得非常重要,它是业务系统中的单点,因此非常重要。
视频播放系统
本文介绍的视频播放系统,是基于网络的视频播放系统,采用最常用的http方式,播放通用格式mp4格式的视频,这种视频可以在大多数浏览器中,智能手机中直接播放。
CDN
CDN的全称是Content Delivery Network,即内容分发网络。其基本思路是尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快、更稳定。通过在网络各处放置节点服务器所构成的在现有的互联网基础之上的一层智能虚拟网络,CDN系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近的服务节点上。其目的是使用户可就近取得所需内容,解决 Internet网络拥挤的状况,提高用户访问网站的响应速度。
DNS
DNS(Domain Name System,域名系统),因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。通过主机名,最终得到该主机名对应的IP地址的过程叫做域名解析(或主机名解析)。
CDN视频播放系统
常规的视频播放系统,直接通过CDN地址进行播放。由于每个地区的用户使用的DNS服务器不一样,因此通过不同DNS服务器解释同一个域名时,给出不同的IP地址,即可实现用户的临近接入播放,提高用户的播放体验。但是传统的DNS方法,由于有些用户的设置错误,可能会调度到非常远的节点上,另外由于没有经过一个统一的调度,当视频出现问题时,如色情视频,恐怖视频等,将无法立即把所有CDN上的内容删除掉,增加风险。
商业CDN的不足
第三方的商业CDN目前已经做得比较好了,但是有几个问题无法解决,一是CDN通过DNS进行调度,这取决于用户的设置是否正确,二是毕竟是商业CDN,会在质量和价格上寻找最优解,例如会使用二线城市的节点服务一线城市,这样成本会便宜很多,在闲时效果不错,但是在高峰时,会由于城市间的骨干网络拥塞造成质量抖动比较严重,三是基于DNS的调度,无法知道节点的容量,例如节点带宽已经非常满了,但是请求还是不对的进入。
IP调度系统的不足
二是CDN会提供基于IP策略的调度,但是这个取决于IP库的精确度,如判断用户在广东,但是其实用户的IP是河北,那么调度的结果就会非常的差。另外目前跨运营商的情况比较严重,很多小运营商的出口是某些大运营商的IP,所以经常有这样的情况,某北京电信通的用户,IP地址是山东联通的IP。
视频播放调度系统
综上所述,如果实现一个高性能的调度系统,通过调度系统,获取用户的真实IP,通过IP的累积数据,能清楚知道目前的情况,包括IP服务节点的远近,好坏,节点的负荷等等,同时判断请求是否非法,视频是否不允许播放等等,再转到对应的CDN点进行服务,能比较好的提升用户体验。
IP库现状
传统的IP数据库,是通过一些官方数据,民间收集,自身上报等等手段实现的,所以数据本身不是很结构化,更有各种各样的信息,给使用造成很多不便。
同时,IP数据日新月异,不断地变化,因此IP库的更新非常重要。
纯真IP库
该数据库出现时间比较早,最早用于QQ客户端显示对方IP使用,能知道对方所在地区,目前这个库还是免费的,还不停有维护,但是缺点是数据格式非常乱,定位数据比较繁琐。
格式详解
纯真ip库只有一个文件QQWry.dat,结构上分为3块:文件头,记录区,索引区。 一般我们要查找IP时,先在索引区查找记录偏移,然后再到记录区读出信息。由于记录区的记录是不定长的,所以直接在记录区中搜索是不可能的。由于记录数比较多,如果我们遍历索引区也会是有点慢的,一般来说,我们可以用二分查找法搜索索引区,其速度比遍历索引区快若干数量级。要注意的是,QQWry.dat里面全部采用了little-endian字节序。文件结构图如下:
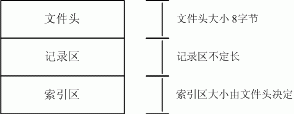
QQWry.dat的文件头只有8个字节,其结构非常简单,首四个字节是第一条索引的绝对偏移,后四个字节是最后一条索引的绝对偏移。
记录区 每条IP记录都由国家和地区名组成,国家地区在这里并不是太确切,因为可能会查出来“清华大学计算机系”之类的,这里清华大学就成了国家名了,所以这个国家地区名和IP数据库制作的时候有关系。所以记录的格式有点像QName,有一个全局部分和局部部分组成,我们这里还是沿用国家名和地区名的说法。
于是我们想象着一条记录的格式应该是: [IP地址][国家名][地区名],当然,这个没有什么问题,但是这只是最简单的情况。很显然,国家名和地区名可能会有很多的重复,如果每条记录都保存一个完整的名称拷贝是非常不理想的,所以我们就需要重定向以节省空间。所以为了得到一个国家名或者地区名,我们就有了两个可能:第一就是直接的字符串表示的国家名,第二就是一个4字节的结构,第一个字节表明了重定向的模式,后面3个字节是国家名或者地区名的实际偏移位置。对于国家名来说,情况还可能更复杂些,因为这样的重定向最多可能有两次。
那么什么是重定向模式?根据上面所说,一条记录的格式是[IP地址][国家记录][地区记录],如果国家记录是重定向的话,那么地区记录是有可能没有的,于是就有了两种情况,我管他叫做模式1和模式2。我们对这些格式的情况举图说明:

IP记录的最简单形式
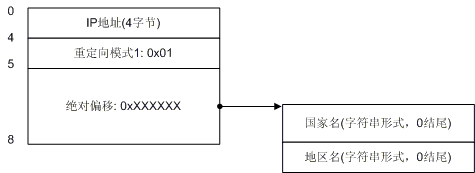
重定向模式1
我们看到在模式1的情况下,地区记录也跟着国家记录走了,在IP地址之后只剩下了国家记录的4字节,后面3个字节构成了一个指针,指向了实际的国家名,然后又跟着地址名。模式1的标识字节是0x01。
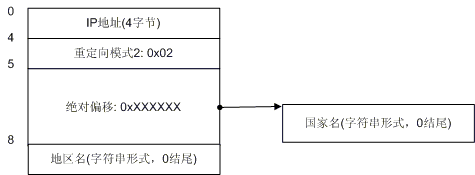
重定向模式2
我们看到了在模式2的情况下(其标识字节是0x02),地区记录没有跟着国家记录走,因此在国家记录之后4个字节之后还是有地区记录。我想你已经明白了模式1和模式2的区别,即:模式1的国家记录后面不会再有地区记录,模式2的国家记录后会有地区记录。下面我们来看一下更复杂的情况。
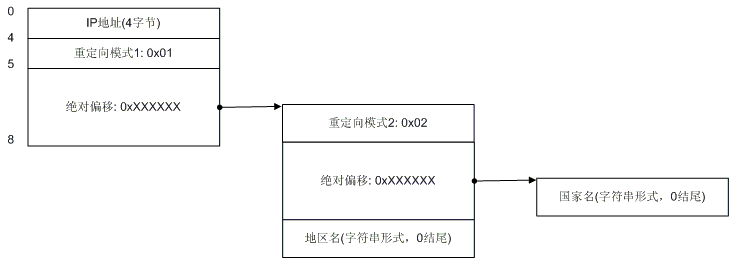
混和情况1
当国家记录为模式1的时候可能出现的更复杂情况,在这种情况下,重定向指向的位置仍然是个重定向,不过第二次重定向为模式2。大家不用担心,没有模式3了,这个重定向也最多只有两次,并且如果发生了第二次重定向,则其一定为模式2,而且这种情况只会发生在国家记录上,对于地区记录,模式1和模式2是一样的,地区记录也不会发生2次重定向。不过,这个图还可以更复杂:
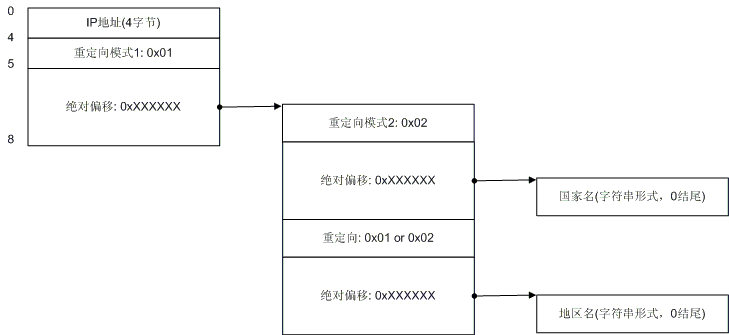
混和情况2
应该也很好理解,只不过地区记录也来重定向而已,有一点我要提醒你,如果重定向的地址是0,则表示未知的地区名。
所以我们总结如下:一条IP记录由[IP地址][国家记录][地区记录]组成,对于国家记录,可以有三种表示方式:字符串形式,重定向模式1和重定向模式2。对于地区记录,可以有两种表示方式:字符串形式和重定向,另外有一条规则:重定向模式1的国家记录后不能跟地区记录。按照这个总结,在这些方式中合理组合,就构成了IP记录的所有可能情况。
设计的理由 在我们继续去了解索引区的结构之前,我们先来了解一下为何记录区的结构要如此设计。我想你可能想到了答案:字符串重用。没错,在这种结构下,对于一个国家名和地区名,我只需要保存其一次就可以了。我们举例说明,为了表示方便,我们用小写字母代表IP记录,C表示国家名,A表示地区名:
有两条记录a(C1, A1), b(C2, A2),如果C1 = C2, A1 = A2,那么我们就可以使用图3显示的结构来实现重用 有三条记录a(C1, A1), b(C2, A2), c(C3, A3),如果C1 = C2, A2 = A3,现在我们想存储记录b,那么我们可以用图6的结构来实现重用 有两条记录a(C1, A1), b(C2, A2),如果C1 = C2,现在我们想存储记录b,那么我们可以采用模式2表示C2,用字符串表示A2
你可以举出更多的情况,你也会发现在这种结构下,不同的字符串只需要存储一次。
在文件头部分,我们说明了文件头实际上是两个指针,分别指向了第一条索引和最后一条索引的绝对偏移。那么索引区如下所示:

文件头指向索引区图示
实在是很简单,不是吗?从文件头你就可以定位到索引区,然后你就可以开始搜索IP了!每条索引长度为7个字节,前4个字节是起始IP地址,后三个字节就指向了IP记录。这里有些概念需要说明一下,什么是起始IP,那么有没有结束IP? 假设有这么一条记录:166.111.0.0 - 166.111.255.255,那么166.111.0.0就是起始IP,166.111.255.255就是结束IP,结束IP就是IP记录中的那头4个字节,这下你应该就清楚了吧。于是乎,每条索引配合一条记录,构成了一个IP范围,如果你要查找166.111.138.138所在的位置,你就会发现166.111.138.138落在了166.111.0.0 - 166.111.255.255 这个范围内,那么你就可以顺着这条索引去读取国家和地区名了。那么我们给出一个最详细的图解吧:
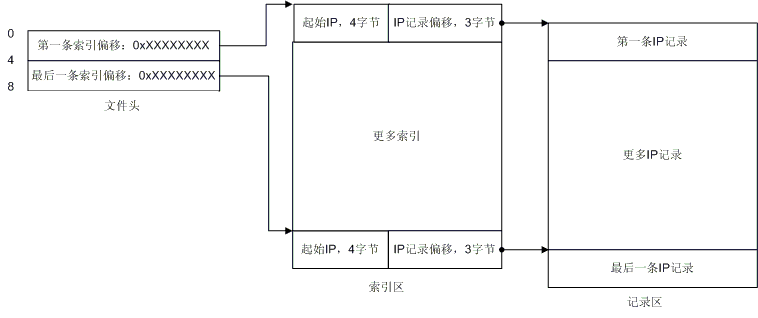
文件详细结构
现在一切都清楚了是不是?也许还有一点你不清楚,QQWry.dat的版本信息存在哪里呢? 答案是:最后一条IP记录实际上就是版本信息,最后一条记录显示出来就是这样:255.255.255.0 255.255.255.255 纯真网络 20XX年X月X日IP数据。OK,到现在你应该全部清楚了。
第三方服务
大公司都有对外使用的IP查询服务,不过都有一定的限制,无法很好地用于商业用途,还有ipip.net 等商业使用的IP库,是需要付费使用的。如:
淘宝:http://ip.taobao.com/service/getIpInfo.php?ip=8.8.8.8
新浪:http://int.dpool.sina.com.cn/iplookup/iplookup.php?format=js&ip=12.130.132.30
搜狐:http://pv.sohu.com/cityjson?ie=utf-8 http://txt.go.sohu.com/ip/soip
实现思路
如何定位关键信息
一个IP可以分为四段,分别命名为A.B.C.D,那么总共有42亿个ip地址,这么多IP我们无法逐一记录的,一个A段IP地址范围是A.X.X.X,共有1600多万种可能,如果C段IP是A.B.C.X,那么这个IP段的表示范围只有256个。
我们假设这256个IP的地理位置,运营商信息都一致,那么所有C段IP就只有1600多万种了,如果一个IP,我们用结构化的2个字节来存储相关信息,那么我们就只需要32MB的大小,就可以把所有C段IP的情况保存下来!
我们把这两个字节的数据,称为IPC码,也就是每个C段IP对应一个IPC码。
并且由于数据是结构化的,定长的,因此我们需要找某个IP对应信息的时候,就只需要直接定位偏移量 (A256256+B256+C)2 这个位置的数据即可!
那么这两个字节我们保存些什么呢?
我们可以根据自身喜好,或系统的需要来划分这些字节。
如:第一位判断是国内还是国外,第2-3位区分四大大区(如国内区分:华北,华中,华南,西部),第4-6位表示省,7-8位表示省的大区,9-11位表示市,12-13位表示区,14-16位表示运营商。
这个区分的好处是很明显的,例如我想知道两个IP之间的远近,可以直接通过异或就能计算得到。如,两个IP市都一样,异或完1-11位全是0,表示非常近了,例如湖南和湖北省,都同属于华中大区,那么1-3位会一样,如果长沙和岳阳,会发现同省1-6位一样。
如何评估质量
如何取得质量数据
每次播放,我们可以在播放完成时进行上报统计,这样能得知最准确的客户播放质量,便于实时修正调度策略。
如何记录质量数据
海量的播放质量数据提交上来后,我们怎样能自动发现其中的问题,并且实时去修正他呢?我们可以通过IPC码进行汇总记录,IPC码只有65536个,那么对应的客户信息也会汇总到一起了。
如何避免信息有误
刚才也提到,如果IP库本身不准,可能会导致服务质量差的问题,而且IP库的更新,都是各大公司的难题,但是如果我们抛开IP库信息,直接使用IPC码进行记录呢?这样就只有对应C段IP的这256个用户的信息才汇总在一起,肯定不会有别人的数据加进来了!