Docker自动化运维
By 陈玺@慧聪
第一章 自动化运维与Docker
什么是自动化运维
IT运维从诞生发展至今,自动化作为其重要属性之一已经不仅仅只是代替人工操作,更重要的是深层探知和全局分析,关注的是在当前条件下如何实现性能与服务最优化,同时保障投资收益最大化。自动化对IT运维的影响,已经不仅仅是人与设备之间的关系,已经发展到了面向客户服务驱动IT运维决策的层面,IT运维团队的构成,也从各级技术人员占大多数发展到业务人员甚至用户占大多数的局面。
因此,IT运维自动化是一组将静态的设备结构转化为根据IT服务需求动态弹性响应的策略,目的就是实现IT运维的质量,降低成本。可以说自动化一定是IT运维最高层面的重要属性之一,但不是全部。
运维自动化的关键在于标准化。当你有一个成熟的团队,有标准化的流程,那么运维自动化就水到渠成了。而如果你什么都没有,那就需要先设定优先级。
我们的目标当然是将所有的流程标准化,而哪些要放在前面做?做起来比较简单的,和比较重要的。我认为构建和测试的流程是最基本的第一步。这对于交付产品的公司来说容易一些,对互联网公司来说更复杂一些,而测试比构建也要复杂一些,但这是基础。构建和测试的流程标准化做好了,就可以准备做自动化的工作了。
我们假设你的团队能够很好的使用Git,然后你建立了构建和测试的标准化流程,然后你就可以用工具来实现自动化。这可能是Jenkins这样的工具,不过Jenkins比较复杂,如果你只是一个很简单的网站,那么自己写一些脚本来实现自动化是更合适的。
到此为止,我们说的还不是自动化运维,而是自动化工具链。工具链就是开发工具链,从IDE,到代码提交,代码审查,构建,到测试,仍然属于开发的范畴。在这之后才是运维的范畴,就是往生产环节部署。
什么是docker
Docker可以是一个更易于创建、部署和运行应用程序的工具。docker允许开发人员将应用程序所有依赖打包成一个镜像。通过这个镜像,开发人员可以放心将应用程序将运行在任何不同环境的设备上,可以是编写和测试代码的任何其他的设备上。
更重要的是Docker是开源的。这意味着任何人都可以贡献代码和扩展它,
默认来说,Docker容器也无法运行cron任务或者batch任务,意味着你没法儿让它自动做备份之类的工作,而这是最基本的运维任务,这是另一个必须解决的问题,否则你根本无法构建一个自动化管理的云环境,而要解决这个问题,你需要搞一些手段,比如改造它的架构,但是你一折腾,又引入了很多新的问题要解决。
总体来说,Docker是一个对开发者非常友好的东西:简单的实现不同机器上的环境标准化,可以轻松拿来拿去,而且在不同的云平台上都支持。而把Docker用起来对运维而言则是很大的挑战。
第二章 Docker自动化编排系统
自动化编排系统简介
Swarm
Swarm允许程序分布在多台计算机,从某种程度上让程序对程序员完全透明。Swarm将会观察程序的执行,并计算出如何在计算机之间分配计算量以达到效率最大化。Swarm采用LGPL许可证,用Scala 2.8语言实现。目前还处于早期发展阶段,Ian制作了一则36分钟长的视频,介绍这种“云的透明化分布式计算(Vimeo)”。
Kubernetes
Kubernetes作为Docker生态圈中重要一员,是Google多年大规模容器管理技术的开源版本,是产线实践经验的最佳表现[G1]。如Urs Hölzle所说,无论是公有云还是私有云甚至混合云,Kubernetes将作为一个为任何应用,任何环境的容器管理框架无处不在。正因为如此, 目前受到各大巨头及初创公司的青睐,如Microsoft、VMWare、Red Hat、CoreOS、Mesos等,纷纷加入给Kubernetes贡献代码。随着Kubernetes社区及各大厂商的不断改进、发展,Kuberentes将成为容器管理领域的领导者。
为什么使用Kubernetes
轻装上阵
首先,直接的感受就是我们可以“轻装上阵”地开发复杂系统了。以前动不动就需要十几个人而且团队里需要不少技术达人一起分工协作才能设计实现和运维的分布式系统,在采用Kubernetes解决方案之后,只需一个精悍的小团队就能轻松应对。在这个团队里,一名架构师专注于系统中“服务组件”的提炼,几名开发工程师专注于业务代码的开发,一名系统兼运维工程师负责Kubernetes的部署和运维,从此再也不用“996”了,这并不是因为我们少做了什么,而是因为Kubernetes已经帮我们做了很多。
全面拥抱微服务架构
其次,使用Kubernetes就是在全面拥抱微服务架构。微服务架构的核心是将一个巨大的单体应用分解为很多小的互相连接的微服务,一个微服务背后可能有多个实例副本在支撑,副本的数量可能会随着系统的负荷变化而进行调整,内嵌的负载均衡器在这里发挥了重要作用。微服务架构使得每个服务都可以由专门的开发团队来开发,开发者可以自由选择开发技术,这对于大规模团队来说很有价值,另外每个微服务独立开发、升级、扩展,因此系统具备很高的稳定性和快速迭代进化能力。谷歌、亚马逊、eBay、NetFlix等众多大型互联网公司都采用了微服务架构,此次谷歌更是将微服务架构的基础设施直接打包到Kubernetes解决方案中,让我们有机会直接应用微服务架构解决复杂业务系统的架构问题。
第三章 Kubernetes简介
相关概念
pod
pod是容器的集合, 每个pod可以包含一个或者多个容器; 为了便于管理一般情况下同一个pod里运行相同业务的容器。
同一个pod的容器共享相同的系统栈(网络,存储)。
同一个pod只能运行在同一个机器上
Replicateion controller
由于这个名字实在是太长了, 以下均用rc代替(kubernetes也知道这个名字比较长, 也是用rc代替)。
rc是管理pod的, rc负责集群中在任何时候都有一定数量的pod在运行, 多了自动杀, 少了自动加;
rc会用预先定义好的pod模版来创建pod; 创建成功后正在运行的pod实例不会随着模版的改变而改变;
rc通过SELECTOR(一种系统label)与pod对应起来
当rc中定义的pod数量改变是, rc会自动是运行中的pod数量与定义的数量一致。
rc还有一种神奇的机制:rolling updates,比如现在某个服务有5个正在运行的pod, 现在pod本身的业务要更新了, 可以以逐个替换的机制来实现整个rc的更新。
service
services即服务, 真正提供服务的接口,将pod提供的服务暴力到外网, 每个服务后端可以有一个或者多个pod。
lable
label就是标签, kubernetes在pod, service, rc上打了很多个标签(K/V形式的键值对); lable的存储在etcd(一个分布式的高性能,持久化缓存)中; kubernetes用etcd一下子解决了传统服务中的服务之间通信(消息服务)与数据存储(数据库)的问题。
架构实现
整个架构大体分为控制节点和计算节点; 控制节点发命令, 计算节点干活.
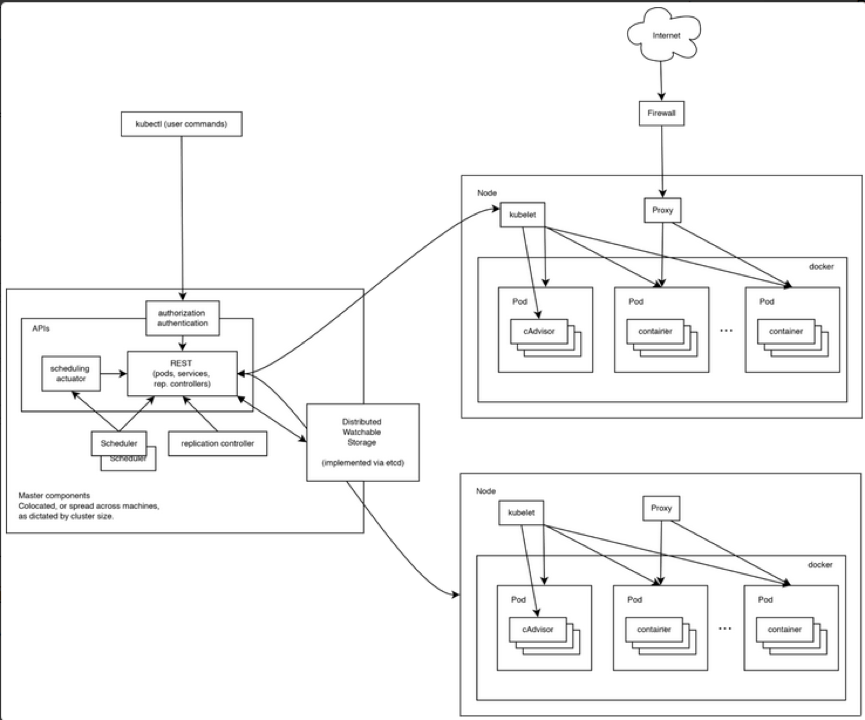
第四章 在Kubernetes中搭建Jenkins使用
部署安装
1.1 规划 Master 192.168.1.11 apiserver、controller-manager、scheduler
etcd 192.168.1.11 etcd
NODE 192.168.1.12 Kubernetes+docker
NODE 192.168.1.13 Kubernetes+docker
1.2 前期准备
(以下步骤在所有服务器上执行)
1.3 停止防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
1.4 配置yum源
tee /etc/yum.repos.d/docker.repo <<-'EOF'
dockerrepo]
name=Docker Repository
baseurl=https://yum.dockerproject.org/repo/main/centos/7/
enabled=1
pgcheck=1
pgkey=https://yum.dockerproject.org/gpg
EOF
1.5 升级系统包
yum update –y
1.5关闭selinux
#cat /etc/sysconfig/selinux
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
1.6 安装kubernetes,自动安装对应版本的docker
yum -y install --enablerepo=virt7-docker-common-release kubernetes flannel
1.7 修改配置文件
证书:
#openssl genrsa -out ca.key 2048
#openssl req -x509 -new -nodes -key ca.key -subj "/CN=test.com" -days 5000 -out ca.crt
#echo subjectAltName=IP:10.254.0.1 > extfile.cnf
#openssl genrsa -out server.key 2048
#openssl req -new -key server.key -subj "/CN=k8s-master.test.com" -out server.csr
#openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out server.crt -days 5000
1.8 Master端
cat /etc/kubernetes/apiserver
###
# kubernetes system config
#
# The following values are used to configure the kube-apiserver
#
# The address on the local server to listen to.
KUBE_API_ADDRESS="--insecure-bind-address=0.0.0.0"
# The port on the local server to listen on.
KUBE_API_PORT="--port=8080"
# Port minions listen on
# KUBELET_PORT="--kubelet-port=10250"
# Comma separated list of nodes in the etcd cluster
KUBE_ETCD_SERVERS="--etcd-servers=http://127.0.0.1:2379"
# Address range to use for services
KUBE_SERVICE_ADDRESSES="--service-cluster-ip-range=10.254.0.0/16"
# default admission control policies
KUBE_ADMISSION_CONTROL="--admission-control=NamespaceLifecycle,NamespaceExists,LimitRanger,SecurityContextDeny,ServiceAccount,ResourceQuota" \
# Add your own!
KUBE_API_ARGS="--client-ca-file=/key1/ca.crt --tls-private-key-file=/key1/server.key --tls-cert-file=/key1/server.crt
--secure-port=443
--log-dir=/var/log/"
cat /etc/kubernetes/config
###
# kubernetes system config
#
# The following values are used to configure various aspects of all
# kubernetes services, including
#
# kube-apiserver.service
# kube-controller-manager.service
# kube-scheduler.service
# kubelet.service
# kube-proxy.service
# logging to stderr means we get it in the systemd journal
KUBE_LOGTOSTDERR="--logtostderr=true"
# journal message level, 0 is debug
KUBE_LOG_LEVEL="--v=0"
# Should this cluster be allowed to run privileged docker containers
KUBE_ALLOW_PRIV="--allow-privileged=false"
# How the controller-manager, scheduler, and proxy find the apiserver
KUBE_MASTER="--master=http://k8s-master.test.com:8080"
cat /etc/kubernetes/controller-manager
###
# The following values are used to configure the kubernetes controller-manager
# defaults from config and apiserver should be adequate
# Add your own!
KUBE_CONTROLLER_MANAGER_ARGS="--log-dir=/var/log/kubernetes --service-account-private-key-file=/key1/server.key --root-ca-file=/key1/ca.crt --master=http://k8s-master.test.com:8080"
#cat /etc/kubernetes/kubelet
###
# kubernetes kubelet (minion) config
# The address for the info server to serve on (set to 0.0.0.0 or "" for all interfaces)
KUBELET_ADDRESS="--address=0.0.0.0"
# The port for the info server to serve on
# KUBELET_PORT="--port=10250"
# You may leave this blank to use the actual hostname
KUBELET_HOSTNAME="--hostname-override=k8s-master.test.com"
# location of the api-server
KUBELET_API_SERVER="--api-servers=http://k8s-master.test.com:8080"
# pod infrastructure container
KUBELET_POD_INFRA_CONTAINER="--pod-infra-container-image=registry.access.redhat.com/rhel7/pod-infrastructure:latest"
# Add your own!
KUBELET_ARGS=""--cluster_dns=10.254.254.254 --cluster_domain=cluster.local --config=/etc/kubernetes/manifests"
cat /etc/kubernetes/proxy
###
# kubernetes proxy config
# default config should be adequate
# Add your own!
KUBE_PROXY_ARGS=""
cat /etc/kubernetes/scheduler
###
# kubernetes scheduler config
# default config should be adequate
# Add your own!
KUBE_SCHEDULER_ARGS="--master=k8s-master.test.com:8080"
1.9 Slave端
cat /etc/kubernetes/apiserver
###
# kubernetes system config
#
# The following values are used to configure the kube-apiserver
#
# The address on the local server to listen to.
KUBE_API_ADDRESS="--insecure-bind-address=127.0.0.1"
# The port on the local server to listen on.
# KUBE_API_PORT="--port=8080"
# Port minions listen on
# KUBELET_PORT="--kubelet-port=10250"
# Comma separated list of nodes in the etcd cluster
KUBE_ETCD_SERVERS="--etcd-servers=http://127.0.0.1:2379"
# Address range to use for services
KUBE_SERVICE_ADDRESSES="--service-cluster-ip-range=10.254.0.0/16"
# default admission control policies
KUBE_ADMISSION_CONTROL="--admission-control=NamespaceLifecycle,NamespaceExists,LimitRanger,SecurityContextDeny,ServiceAccount,ResourceQuota"
# Add your own!
KUBE_API_ARGS=""
cat /etc/kubernetes/config
###
# kubernetes system config
#
# The following values are used to configure various aspects of all
# kubernetes services, including
#
# kube-apiserver.service
# kube-controller-manager.service
# kube-scheduler.service
# kubelet.service
# kube-proxy.service
# logging to stderr means we get it in the systemd journal
KUBE_LOGTOSTDERR="--logtostderr=true"
# journal message level, 0 is debug
KUBE_LOG_LEVEL="--v=0"
# Should this cluster be allowed to run privileged docker containers
KUBE_ALLOW_PRIV="--allow-privileged=false"
# How the controller-manager, scheduler, and proxy find the apiserver
KUBE_MASTER="--master=http://k8s-master.test.com:8080"
# cat /etc/kubernetes/controller-manager
###
# The following values are used to configure the kubernetes controller-manager
# defaults from config and apiserver should be adequate
# Add your own!
KUBE_CONTROLLER_MANAGER_ARGS=""
cat /etc/kubernetes/kubelet
###
# kubernetes kubelet (minion) config
# The address for the info server to serve on (set to 0.0.0.0 or "" for all interfaces)
KUBELET_ADDRESS="--address=0.0.0.0"
# The port for the info server to serve on
# KUBELET_PORT="--port=10250"
# You may leave this blank to use the actual hostname
KUBELET_HOSTNAME="--hostname-override=test12.test.com"
# location of the api-server
KUBELET_API_SERVER="--api-servers=http://k8s-master.test.com:8080"
# pod infrastructure container
KUBELET_POD_INFRA_CONTAINER="--pod-infra-container-image=registry.access.redhat.com/rhel7/pod-infrastructure:latest"
# Add your own!
KUBELET_ARGS="--cluster_dns=10.254.254.254 --cluster_domain=cluster.local --config=/etc/kubernetes/manifests"
cat /etc/kubernetes/scheduler
###
# kubernetes scheduler config
# default config should be adequate
# Add your own!
KUBE_SCHEDULER_ARGS=""
cat /etc/kubernetes/proxy
###
# kubernetes proxy config
# default config should be adequate
# Add your own!
KUBE_PROXY_ARGS="--master=k8s-master.test.com:8080"
1.10 所有节点hosts配置
K8s-master.test.com 192.168.1.11
Test12.test.com 192.168.1.12
Test13.test.com 192.168.1.13
1.11 启动服务
#systemctl enable kube-apiserver; (master)
#systemctl enable kube-controller-manager; (master,slave)
#systemctl enable kube-proxy; (master,slave)
#systemctl enable kubelet; (master,slave)
#systemctl enable kube-scheduler; (master,slave)
#systemctl start kube-apiserver; (master)
#systemctl start kube-controller-manager; (master,slave)
#systemctl start kube-proxy; (master,slave)
#systemctl start kubelet; (master,slave)
#systemctl start kube-scheduler; (master,slave)
1.12 获取集群状态:
kubectl get nodes
NAME STATUS AGE
test12.test.com Ready 40d
test12.test.com Ready 40d
第五章 测试系统
部署自动化测试系统:Jenkins
1. 准备 docker 镜像
#jenkins master
jenkins:2.7.2
#jenkins slave
jenkinsci/jnlp-slave:2.52
2. 部署 jenkins master
Rc:
cat jenkins-server-rc.yaml
apiVersion: "v1"
kind: "ReplicationController"
metadata:
name: "jenkins"
labels:
name: "jenkins"
spec:
replicas: 1
template:
metadata:
name: "jenkins"
labels:
name: "jenkins"
spec:
containers:
- name: "jenkins"
image: "jenkins:2.7.2"
ports:
- containerPort: 8080
- containerPort: 50000
volumeMounts:
- name: "jenkins-data"
mountPath: "/var/jenkins_home"
volumes:
- name: "jenkins-data"
hostPath:
path: "/var/jenkins"
svc:
cat jenkins-server-svc.yaml
apiVersion: "v1"
kind: "Service"
metadata:
name: "jenkins"
spec:
type: "NodePort"
selector:
name: "jenkins"
type: NodePort
ports:
-
name: "http"
port: 8080
protocol: "TCP"
nodePort: 30280
-
name: "slave"
port: 50000
protocol: "TCP"
3. 安装 jenkins Kubernetes 插件
登录 jenkins master,根据页面提示,输入 /home/jenkins_home/下的密钥文件里的密钥,进入插件安装界面,选择 Kubernetes Plugin 安装。
4. 创建 jenkins Kubernetes 云
jenkins-系统管理-系统设置-云-Kubernetes:
Name: k8s_cluster Kubernetes URL: https://kubernetes.default Kubernetes Namespace: default Jenkins URL: http://jenkins.default:8080
images - Kubernetes Pod Template: Name: jnlp-slave Labels: jnlp-slave Docker image: jnlp-slave:
Jenkins slave root directory: /home/jenkins
5. 查看无任务状态
5.1 jenkins
节点中只有一个master,没有 slave节点
5.2 kubernetes
只有 jenkins master pod
6. 创建测试任务
该任务选择标签为 jnlp-slave 的镜像作为执行任务的容器的镜像,构建动作是 ping www.baidu.com
建好后执行该任务
7. 查看任务执行状态
7.1 jenkins
jenkins 自动创建了一个slave节点
7.2 kubernetes
kubernetes pod中多出一个jnlp-slave-开头的pod
8. 结束任务
结束任务后,刚才看到的slave 节点被自动删除,kubernetes 中 jnlp-slave 开头的 pod 也消失了。
第六章 监控系统
Kubernetes部署监控(Heapster+Influxdb+Grafana)
Heapster用于采集k8s集群中node和pod资源的数据,其通过node上的kubelet来调用cadvisor API接口;之后进行数据聚合传至后端存储系统。
Heapster当前版本需使用https安全方式与master连接,
1.master主机创建证书并应用: (之前已创建)
apiserver启动成功后,系统会为每个命名空间创建一个ServiceAccount和一个Secret(包含一个ca.crt和一个token)
[root@k8s_master kubernetes]# kubectl get serviceaccounts --all-namespaces
NAMESPACE NAME SECRETS AGE
default default 1 6h
development default 1 4h
[root@k8s_master kubernetes]# kubectl get secrets --all-namespaces
NAMESPACE NAME TYPE DATA AGE
default default-token-iegn7 kubernetes.io/service-account-token 2 10m
development default-token-xozsi kubernetes.io/service-account-token 2 10m
[root@k8s_master kubernetes]# kubectl describe secret default-token-iegn7
[root@k8s_master kubernetes]# kubectl describe secret default-token-xozsi --namespace=development
可以看到生成的token
新建pod,查看容器内的crt证书和token(自动生成)
[root@k8s_master pods]# kubectl create -f frontend-controller.yaml
replicationcontroller "frontend" created
[root@k8s_master pods]# kubectl get rc
CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS AGE
frontend frontend kubeguide/guestbook-php-frontend name=frontend 1 5s
[root@k8s_master pods]# kubectl get pods
NAME READY STATUS RESTARTS AGE
frontend-z7021 1/1 Running 0 7s
[root@k8s_master pods]# kubectl get pods frontend-z7021 -o yaml
......
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: default-token-iegn7
readOnly: true
.....
volumes:
- name: default-token-iegn7
secret:
secretName: default-token-iegn7
[root@k8s_master pods]# kubectl exec -ti frontend-z7021 ls /var/run/secrets/kubernetes.io/serviceaccount
ca.crt token
2.部署Influxdb+grafana
cat influxdb-grafana-controller.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: monitoring-influxdb-grafana-v3
namespace: kube-system
labels:
k8s-app: influxGrafana
version: v3
kubernetes.io/cluster-service: "true"
spec:
replicas: 1
selector:
k8s-app: influxGrafana
version: v3
template:
metadata:
labels:
k8s-app: influxGrafana
version: v3
kubernetes.io/cluster-service: "true"
spec:
containers:
- image: gcr.io/google_containers/heapster_influxdb:v0.5
name: influxdb
resources:
# keep request = limit to keep this container in guaranteed class
limits:
cpu: 100m
memory: 500Mi
requests:
cpu: 100m
memory: 500Mi
ports:
- containerPort: 8083
- containerPort: 8086
volumeMounts:
- name: influxdb-persistent-storage
mountPath: /data
- image: gcr.io/google_containers/heapster_grafana:v2.6.0-2
name: grafana
env:
resources:
# keep request = limit to keep this container in guaranteed class
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
env:
# This variable is required to setup templates in Grafana.
- name: INFLUXDB_SERVICE_URL
value: http://monitoring-influxdb:8086
# The following env variables are required to make Grafana accessible via
# the kubernetes api-server proxy. On production clusters, we recommend
# removing these env variables, setup auth for grafana, and expose the grafana
# service using a LoadBalancer or a public IP.
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
value: /
volumeMounts:
- name: grafana-persistent-storage
mountPath: /var
volumes:
- name: influxdb-persistent-storage
emptyDir: {}
- name: grafana-persistent-storage
emptyDir: {}
cat influxdb-service.yaml
apiVersion: v1
kind: Service
metadata:
name: monitoring-influxdb
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
kubernetes.io/name: "InfluxDB"
spec:
type: NodePort
ports:
- name: http
port: 8083
targetPort: 8083
nodePort: 30083
- name: api
port: 8086
targetPort: 8086
nodePort: 30086
selector:
k8s-app: influxGrafana
cat grafana-service.yaml
apiVersion: v1
kind: Service
metadata:
name: monitoring-grafana
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
kubernetes.io/name: "Grafana"
spec:
# On production clusters, consider setting up auth for grafana, and
# exposing Grafana either using a LoadBalancer or a public IP.
# type: LoadBalancer
type: NodePort
ports:
- port: 80
targetPort: 3000
nodePort: 30080
selector:
k8s-app: influxGrafana
3.部署Heapster,连接influxdb,数据库名k8s
cat heapster-controller.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: heapster-v1.0.2
namespace: kube-system
labels:
k8s-app: heapster
kubernetes.io/cluster-service: "true"
version: v1.0.2
spec:
replicas: 1
selector:
matchLabels:
k8s-app: heapster
version: v1.0.2
template:
metadata:
labels:
k8s-app: heapster
version: v1.0.2
spec:
containers:
- image: gcr.io/google_containers/heapster:v1.0.2
name: heapster
resources:
# keep request = limit to keep this container in guaranteed class
limits:
cpu: 100m
memory: 220Mi
requests:
cpu: 100m
memory: 220Mi
command:
- /heapster
- --source=kubernetes:https://10.254.0.1:443?auth=
- --sink=influxdb:http://monitoring-influxdb:8086
- --metric_resolution=60s
- image: gcr.io/google_containers/heapster:v1.0.2
name: eventer
resources:
# keep request = limit to keep this container in guaranteed class
limits:
cpu: 100m
memory: 207300Ki
requests:
cpu: 100m
memory: 207300Ki
command:
- /eventer
- --source=kubernetes:https://10.254.0.1:443?auth=
- --sink=influxdb:http://monitoring-influxdb:8086
- image: gcr.io/google_containers/addon-resizer:1.0
name: heapster-nanny
resources:
limits:
cpu: 50m
memory: 100Mi
requests:
cpu: 50m
memory: 100Mi
env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
command:
- /pod_nanny
- --cpu=100m
- --extra-cpu=0m
- --memory=220Mi
- --extra-memory=4Mi
- --threshold=5
- --deployment=heapster-v1.0.2
- --container=heapster
- --poll-period=300000
- image: gcr.io/google_containers/addon-resizer:1.0
name: eventer-nanny
resources:
limits:
cpu: 50m
memory: 100Mi
requests:
cpu: 50m
memory: 100Mi
env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
command:
- /pod_nanny
- --cpu=100m
- --extra-cpu=0m
- --memory=207300Ki
- --extra-memory=500Ki
- --threshold=5
- --deployment=heapster-v1.0.2
- --container=eventer
- --poll-period=300000
cat heapster-service.yaml
kind: Service
apiVersion: v1
metadata:
name: heapster
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
kubernetes.io/name: "Heapster"
spec:
ports:
- port: 80
targetPort: 8082
selector:
k8s-app: heapster
4. 登陆grafana,修改连接的数据库为k8s
5、查看集群设备状态
第七章 日志系统
Kubernetes日志系统(fluentd+elasticsearch+grafana)
关于k8s日志,这里简单总结几点:
通过命令行和API查询的日志的生命周期与Pod相同,也就是说Pod重启之后之前的日志就不见了。
为了解决上述问题,可以通过“集群级别日志”技术来获取Pod的历史日志。
k8s支持多种类型的“集群级别日志”,我们的产品使用的是Elasticsearch。
k8s会在每个node上启动一个Fluentd agent Pod来收集当前节点的日志。
k8s会在整个集群中启动一个Elasticsearch Service来汇总整个集群的日志。
上述内容可以通过kubectl get pod/rc/service –namespace=kube-system来查看。
我们可以通过Elasticsearch API来按条件查询日志。
Elasticsearch URL可以通过kubectl cluster-info指令查看
日志系统构建
创建ServiceAccount
cat service-account.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: elasticsearch
创建 Elasticsearch
cat es-controller-k8s.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: es
labels:
component: elasticsearch
spec:
replicas: 1
template:
metadata:
labels:
component: elasticsearch
spec:
serviceAccount: elasticsearch
containers:
- name: es
securityContext:
capabilities:
add:
- IPC_LOCK
image: quay.io/pires/docker-elasticsearch-kubernetes:1.7.1-4
env:
- name: KUBERNETES_CA_CERTIFICATE_FILE
value: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: "CLUSTER_NAME"
value: "myesdb"
- name: "DISCOVERY_SERVICE"
value: "elasticsearch"
- name: NODE_MASTER
value: "true"
- name: NODE_DATA
value: "true"
- name: HTTP_ENABLE
value: "true"
ports:
- containerPort: 9200
name: http
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
volumeMounts:
- mountPath: /data
name: storage
volumes:
- name: storage
emptyDir: {}
cat es-service-k8s.yaml
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
labels:
component: elasticsearch
spec:
type: LoadBalancer
selector:
component: elasticsearch
type: NodePort
ports:
- name: http
port: 9200
protocol: TCP
- name: transport
port: 9300
protocol: TCP
创建kibana
cat kibana-controller.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: kibana-logging-v1
# namespace: kube-system
labels:
k8s-app: kibana-logging
version: v1
kubernetes.io/cluster-service: "true"
spec:
replicas: 1
selector:
k8s-app: kibana-logging
version: v1
template:
metadata:
labels:
k8s-app: kibana-logging
version: v1
kubernetes.io/cluster-service: "true"
spec:
containers:
- name: kibana-logging
image: gcr.io/google_containers/kibana:1.3
resources:
# keep request = limit to keep this container in guaranteed class
limits:
cpu: 100m
requests:
cpu: 100m
env:
- name: "ELASTICSEARCH_URL"
value: "http://elasticsearch:9200"
ports:
- containerPort: 5601
name: ui
protocol: TCP
cat kibana-service.yaml
apiVersion: v1
kind: Service
metadata:
name: kibana-logging
# namespace: kube-system
labels:
k8s-app: kibana-logging
kubernetes.io/cluster-service: "true"
kubernetes.io/name: "Kibana"
spec:
type: NodePort
ports:
- port: 5601
protocol: TCP
targetPort: ui
selector:
k8s-app: kibana-logging
在所有的node节点上配置fluentd
cat /etc/kubernetes/manifests/fluentd-es.yaml
apiVersion: v1
kind: Pod
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
containers:
- name: fluentd-elasticsearch
image: gcr.io/google_containers/fluentd-elasticsearch:1.15
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
第八章 总结
kubernetes是第一个将“一切以服务(Service)为中心,一切围绕服务运转”作为指导思想的创新型产品,它的功能和架构设计自始至终都遵循了这一指导思想,构建在Kubernetes上的系统不仅可以独立运行在物理机、虚拟机集群或者企业私有云上,也可以被托管在公有云中。Kubernetes方案的另一个亮点是自动化,在Kubernetes的解决方案中,一个服务可以自我扩展、自我诊断,并且容易升级,在收到服务扩容的请求后,Kubernetes会触发调度流程,最终在选定的目标节点上启动相应数量的服务实例副本,这些副本在启动成功后会自动加入负责均衡器中并生效,整个过程无须额外的人工操作。另外,Kubernetes会定时巡查每个服务的所有实例的可用性,确保服务实例的数量始终保持为预期的数量,当它发现某个实例不可用时,会自动重启该实例或者在其他节点重新调度、运行一个新实例,这样,一个复杂的过程无须人工干预即可全部自动化完成。
试想一下,如果一个包括几十个节点且运行着几万个容器的复杂系统,其负载均衡、故障检测和故障修复等都需要人工介入进行处理、那将是多么难以想象。