基于日志收集的调用链监控、管理系统
By 李玉福@农信互联
背景
互联网应用的各种服务通常都是用复杂大规模分布式集群来实现的。而这些互联网应用又构建在不同的软件模块集上,这些软件模块,有可能是由不同的团队开发、可能使用不同的编程语言来实现、有可能布在了几千台服务器,横跨多个不同的数据中心。因此,就需要一些可以帮助理解系统行为、用于分析性能问题的工具。
对于分布式在线服务,数以百计的分布式服务构成,每一个请求路由过来后,会经过多个业务系统并留下足迹,并产生对各种Cache或DB的访问,但是这些分散的数据对于问题排查,或是流程优化都帮助有限。一个请求需要经过系统中多个模块,上百台机器的协作完成单次请求,典型场景,单靠人力无法掌握整个请求中各个阶段的性能开销,更无法快速的定位系统中性能瓶颈。对于这么一个跨进程/跨线程的场景,汇总收集并分析海量日志就显得尤为重要。要能做到追踪每个请求的完整调用链路,收集调用链路上每个服务的性能数据,计算性能数据和比对性能指标(SLA),甚至在更远的未来能够再反馈到服务治理中,那么这就是分布式跟踪的目标了。在业界,twitter 的 zipkin 和淘宝的鹰眼就是类似的系统,它们都起源于 Google Dapper 论文,就像历史上 Hadoop 发源于 Google Map/Reduce 论文,HBase 源自 Google BigTable 论文一样。 好了,整理一下,Google叫Dapper,淘宝叫鹰眼,Twitter叫ZipKin,京东商城叫Hydra,eBay叫Centralized Activity Logging (CAL),大众点评网叫CAT,我们叫Lothar
这样的系统通常有几个设计目标:
- 低侵入性——作为非业务组件,应当尽可能少侵入或者无侵入其他业务系统,对于使用方透明,减少开发人员的负担;
- 灵活的应用策略——可以(最好随时)决定所收集数据的范围和粒度;
- 时效性——从数据的收集和产生,到数据计算和处理,再到最终展现,都要求尽可能快;
- 决策支持——这些数据是否能在决策支持层面发挥作用,特别是从 DevOps 的角度;
- 可视化才是王道。
调用链监控、管理系统就为了解决以上这些问题而设计的。
理论依据
Google的论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》是我们设计开发的指导思想(原文和译文地址 https://github.com/bigbully/Dapper-translation)。Google针对自己的分布式跟踪系统Dapper 在生产环境下运行两年多时间积累的经验,在论文中重点提到了分布式跟踪系统对业务系统的零侵入这个先天优势,并总结了大量的应用场景,还提及它的不足之 处。我们通过对这篇论文的深入研究,并参考了Twitter同样依据这篇论文的scala实现Zipkin,结合我们自身的现有架构,我们认为分布式跟踪 系统在我们内部是非常适合的,而且也是急需的。
功能概述
调用链监控、管理系统功能并不复杂,他可以接入一些基础组件,然后实现在基础组件上收集在组建上产生的行为的时间消耗,并且提供跟踪查询页面,对跟踪到的数据进行查询和展示。
领域模型
分布式跟踪的领域模型其实已经很成熟,早在1997年IBM就把ARM2.0(Application Response Measurement)作为一个公开的标准提供给了Open Group,无奈当时SOA的架构还未成熟,对业务的跟踪还需要直接嵌入到业务代码中,致使跟踪系统无法顺利推广。
如今互联网领域大多数后台服务都已经完成了SOA化,所以对业务的跟踪可以直接简化为对服务调用框架的跟踪,所以越来越多的跟踪系统也涌现出来。 在hydra系统中,我们使用的领域模型参考了Google的Dapper和Twitter的Zipkin(http://twitter.github.io/zipkin/)。
分布式调用跟踪系统的设计
分布式调用跟踪系统的设计目标
低侵入性,应用透明
作为非业务组件,应当尽可能少侵入或者无侵入其他业务系统,对于使用方透明,减少开发人员的负担
低损耗
服务调用埋点本身会带来性能损耗,这就需要调用跟踪的低损耗,实际中还会通过配置采样率的方式,选择一部分请求去分析请求路径
大范围部署,扩展性
作为分布式系统的组件之一,一个优秀的调用跟踪系统必须支持分布式部署,具备良好的可扩展性
埋点和生成日志
埋点即系统在当前节点的上下文信息,可以分为客户端埋点、服务端埋点,以及客户端和服务端双向型埋点。
埋点日志通常要包含以下内容:
- TraceId、RPCId、调用的开始时间,调用类型,协议类型,调用方ip和端口,请求的服务名等信息; 调用耗时,调用结果,异常信息,消息报文等; 预留可扩展字段,为下一步扩展做准备;
抓取和存储日志
日志的采集和存储有许多开源的工具可以选择,一般来说,会使用离线+实时的方式去存储日志,主要是分布式日志采集的方式。我们直接采用基于Log4j2的MQ组件将日志推送给kafka。
分析和统计调用链数据
一条调用链的日志散落在调用经过的各个服务器上,首先需要按 TraceId 汇总日志,然后按照RpcId 对调用链进行顺序整理。调用链数据不要求百分之百准确,可以允许中间的部分日志丢失。
将分析后的数据存储到Mysql用于展示系统的数据读取
计算和展示
汇总得到各个应用节点的调用链日志后,可以针对性的对各个业务线进行分析。需要对具体日志进行整理,进一步储存在HBase或者关系型数据库中,可以进行可视化的查询。
核心处理流程
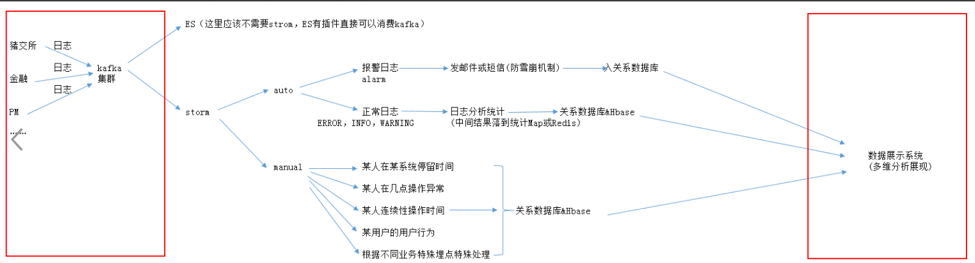
做好日志的收集信息后,下一步就是处理和分析,从上面的配置看我们将日志已经同步收集到kafka中间件上,接下来我们要做的就是如何利用工具和程序去分析、处理日志,否则收集的日志没有任何价值,我们需要做到对日志的实时分析,同时也需要将日志存储,以便后期做离线的日志分析,下面是我们日志分析系统的整个架构图
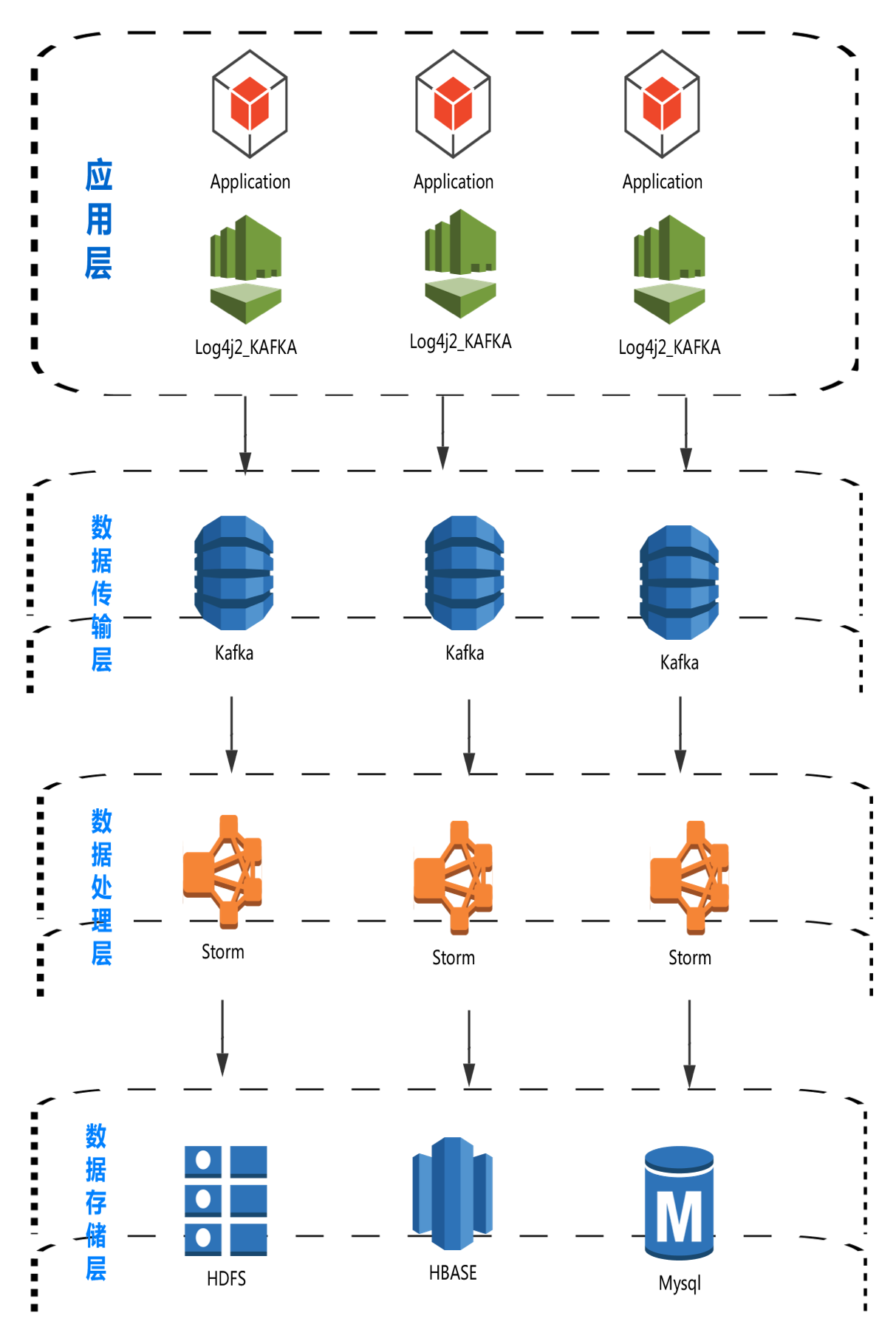
- 整个系统分为四层:Collector层、 transport层、Processor层和Store层。其中Collector层每个机器依赖Log4j配置appender将,负责对单机的日志收集工作;transport层部署Kafka,负责接收Collector层发送的日志,数据处理层通过订阅获取实时的日志信息,处理后将分析结果存储到结构化数据库中,同时将原始文件写入HDFS;Store层负责提供永久的日志文件存储和数据分析结果存储。
- Collector到transport层使用failover策略,防止kafka的单点故障问题,将所有的日志均衡地发到所有的Kafka节点上,达到负载均衡的目标,同时并处理单个Kafka失效的问题。
- transport给Storm系统提供实时日志流,Storm系统通过分析后将结果按照不同的业务路由存储到不同Store层的目标主要有三个:Hdfs, Hbase和Mysql。分别提供离线的数据到Hdfs,结果数据到Habsehe Mysql。
- 对于Storm来说,Hdfs负责永久地存储所有日志;Mysql存储一些固有的分析结果,HBASE存储一些动态的分析结果。
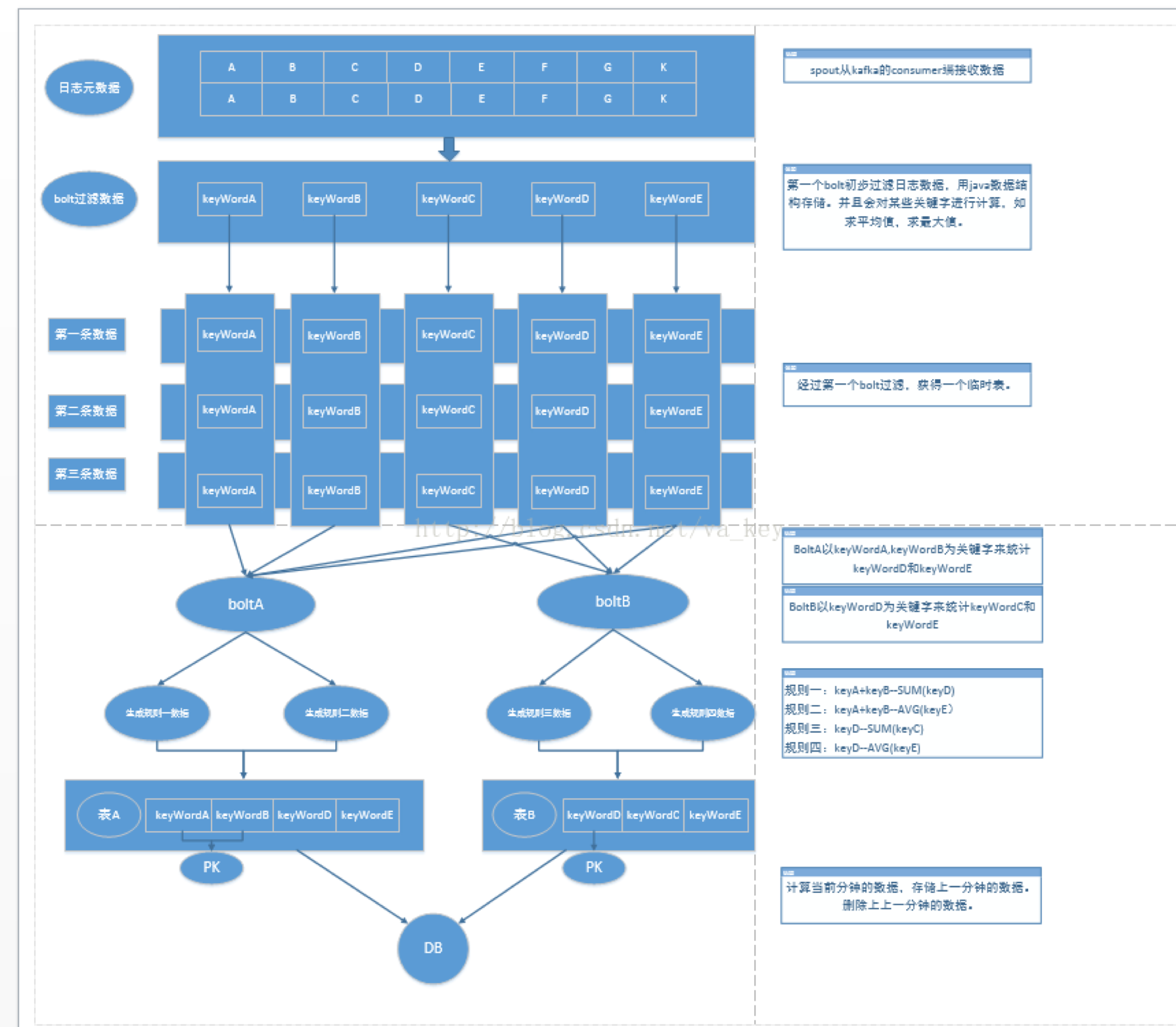 流式计算数据流图
流式计算数据流图
基于Log4j2的统一格式
日志进行统一处理,一个统一、规范的日志格式就是非常重要的,而我们以往使用的 PatternLayout,主要用于人眼查看,而对于系统的分析和处理很不方面,特别是字段的切分非常的不方便,如下所示:
2016-05-08 19:32:55,572 [INFO ] [main] - [com.nxin.log.demo.log4j.Demo.main(Demo.java:13)] 输出信息......
2016-05-08 19:32:55,766 [DEBUG] [main] - [com.nxin.log.demo.log4j.Demo.main(Demo.java:15)] 调试信息......
2016-05-08 19:32:55,775 [WARN ] [main] - [com.nxin.log.demo.log4j.Demo.main(Demo.java:16)] 警告信息......
2016-05-08 19:32:55,783 [ERROR] [main] - [com.nxin.log.demo.log4j.Demo.main(Demo.java:20)] 处理业务逻辑的时候发生一个错误......
java.lang.Exception: 错误消息啊
at com.banksteel.log.demo.log4j.Demo.main(Demo.java:18)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144)
如何去解析这个日志,是个非常头疼的地方,万一某个系统的开发人员输出的日志不符合既定规范的 PatternLayout 就会引发异常。
为了能够一劳永逸的解决格式问题,我们采用JSON格式来统一分析需要的日志格式, 就能很好的规范日志输出,例如LOG4J2.X 版本天然提供JsonLayout支持Json而老版本的1.X,需要自己实现Json输出参考https://github.com/logstash/log4j-jsonevent-layout ,建议统一改为Log4j2.x,输出的格式如下所示:
{
"timeMillis": 1,
"thread": "MyThreadName",
"level": "DEBUG",
"loggerName": "a.B",
"marker": {
"name": "Marker1",
"parents": [{
"name": "ParentMarker1",
"parents": [{
"name": "GrandMotherMarker"
}, {
"name": "GrandFatherMarker"
}]
}, {
"name": "GrandFatherMarker"
}]
},
"message": "Msg",
"thrown": {
"cause": {
"commonElementCount": 27,
"extendedStackTrace": [{
"class": "org.apache.logging.log4j.core.layout.LogEventFixtures",
"method": "createLogEvent",
"file": "LogEventFixtures.java",
"line": 53,
"exact": false,
"location": "test-classes/",
"version": "?"
}],
"localizedMessage": "testNPEx",
"message": "testNPEx",
"name": "java.lang.NullPointerException"
}, {
"class": "org.eclipse.jdt.internal.junit.runner.RemoteTestRunner",
"method": "runTests",
"file": "RemoteTestRunner.java",
"line": 683,
"exact": true,
"location": ".cp/",
"version": "?"
},{
"class": "org.eclipse.jdt.internal.junit.runner.RemoteTestRunner",
"method": "main",
"file": "RemoteTestRunner.java",
"line": 197,
"exact": true,
"location": ".cp/",
"version": "?"
}],
"localizedMessage": "I am suppressed exception 2",
"message": "I am suppressed exception 2",
"name": "java.lang.IndexOutOfBoundsException"
}]
},
"loggerFQCN": "f.q.c.n",
"endOfBatch": false,
"contextMap": [{
"key": "MDC.B",
"value": "B_Value"
}, {
"key": "MDC.A",
"value": "A_Value"
}],
"contextStack": ["stack_msg1", "stack_msg2"],
"source": {
"class": "org.apache.logging.log4j.core.layout.LogEventFixtures",
"method": "createLogEvent",
"file": "LogEventFixtures.java",
"line": 54
}
}
为了更好的过渡,我们保留原来PatternLayout输出到控制台,便于调试,同时增加格式化json的输出,具体配置过程如下。
引入相关jar包
compile group: 'org.apache.logging.log4j', name: 'log4j-slf4j-impl', version: '2.4.1'
compile group: 'org.apache.logging.log4j', name: 'log4j-api', version: '2.6.1'
compile group: 'org.apache.logging.log4j', name: 'log4j-core', version: '2.6.1'
compile group: 'com.fasterxml.jackson.core', name: 'jackson-core', version:'2.7.1'
compile group: 'com.fasterxml.jackson.core', name: 'jackson-databind', version:'2.7.1'
新建log4j2配置文件,文件名log4j2.xml,内容如下:
<?xml version="1.0" encoding="UTF-8"?>
为了能够针对业务系统的异常进行及时的报警、解决线上关键文件,业务系统开发人员可通过日志输出error级别的日志,error里面的内容必须是json格式,提示关键属性key规定如下:
日志报警及监控
{
sysid:系统ID
alarm:[true\false] 是否报警,默认false
msgtype:[sms\email] 通知方式,
sysidto:发送需要通知的系统干系人,
content:通知内容
}
举个例子:
{
"mdc":{},
"line_number":"29",
...
"message": "{
\"sysid\": 2,
\"alarm\": \"true\",
\"sysidto\": [5, 13, ...],
\"content\": \"调用用户中心接口异常。\"
}",
"@timestamp":"2014-01-27T19:52:35.738Z",
"level":"INFO",
"file":"EchoFormServlet.java",
"method":"doPost",
"logger_name":"org.eclipse.jetty.examples.logging.EchoFormServlet"
}
系统实现
日志关键数据
日志以下面的格式形式打到kafka内(不同的系统进kafka不同的topic)
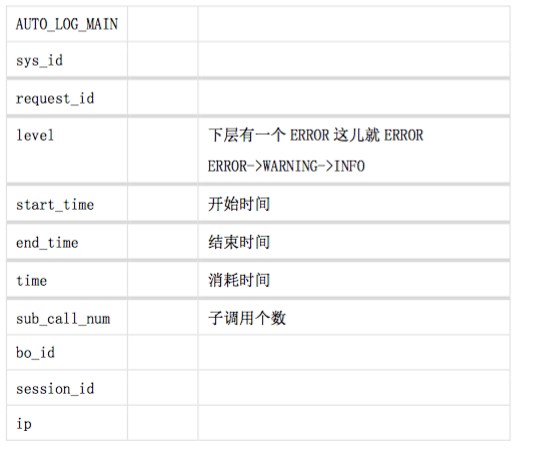
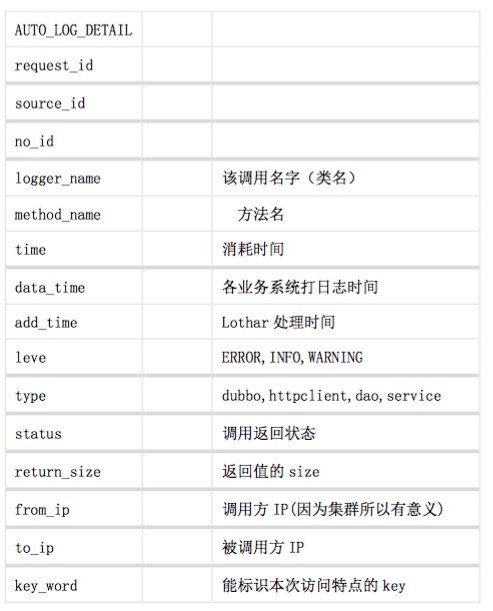
| main_stru | sub_stru | remark | ||
|---|---|---|---|---|
| 1 | sys_id | 3(pm), 24(大数据)等 | ||
| 2 | level | 分为ERROR,INFO,WARNING | ||
| 3 | msg | action(动作) | 后续业务埋点用 | |
| specialPoint | 后续业务埋点用 | |||
| 4 | time_mills | 日志时间 | ||
| 5 | thread_name | 线程名字 | ||
| 6 | logger_name | 该调用名字(类名) | ||
| 7 | method_name | 方法名 | ||
| 8 | time | 消耗的时间 | ||
| 9 | log_type | auto,manual区分出来auto为AOP的自动log,manual为业务埋点log | ||
| 10 | request_id | 用来区分每次req->respon的唯一标识 | ||
| 11 | source_id | 来源编号 | ||
| 12 | no_id | 如果要体系调用层级概念 | ||
| 13 | bo_id | |||
| 14 | session_id | |||
| 15 | ip |
日志实时处理流程图
发消息防雪崩机制
如果某些条件下一些系统连续alarm日志,这时要来者不拒发消息就可能导致消息系统崩溃,甚至一系列其它系统雪崩。
为防止这些这里每发完一条消息就向redis存一条信息并设置过期时间,每发消息时都要看一下redis里是否已发,直到该消息在redis失效
上代码:
//防止系统雪崩,如果一直报一个错就间隔十分钟发一次警告,把发送过的放到redis里设置过期时间,过期时间内不重复发送。
Object reSendFlg = jedisCommands.get(Constants.ALARM_MSG_KEY+sendToArr[i]);
if(reSendFlg==null){
String res = SendMsgUtil.sendMail(sendToArr[i], msg_content);
// 发送成功会把发送信息放到redis里并设置过期时间
if(res!=null && res.indexOf(Constants.RESULT_OK)>-1){
jedisCommands.set(Constants.ALARM_MSG_KEY+sendToArr[i],msg_content,"NX","EX",600);
}
}
流数据处理实时计算的高性能设计
MapTimes设计
当有AUTO_LOG_MAIN这种统计计算业务时,典型bolt处理没办法完成,这里设计了个计时处理的Map
上代码:
/**
* Created by scx on 2016/9/28. */ public class MapTimes { //time主属性 用于存放 需要保存的字段 private static Map
关于这种临时数据存储的一些思考:
MapTimes :适合时序性很短的流数据,实时计算性能很高,封装较难(线程安全阿,空间回收阿,如何触发阿等),可存储的数据量很小(由分配内存决定)吃内存,没有容灾性。
redis:适合时序性较长的流数据处理,实时的计算性能较差(虽是内存数据库但有网络开销),容量阿容灾性啥的可以外包给刘洋老师(^o^)/~
hbase:能实时处理所以时序数据场合(可以愉快的跑个MapReduce都能跑出来的时间以内的时序),实时计算能力较redis差,但容量大大的,数据安全可靠。
hbase-->OpenTSDB-->influxdb(已闭源,等着七牛吧) hbase不只能落临时数据,最终的数据如果量很大也可以落到Hbase。页面展现直接查询Hbase。
以上,可以根据不同业务选不同的技术栈
HikariCP连接池的简单封装
HikariCP是新一代的连接池秒杀c3p0比dbcp和druid效率高一个数量级。看到jdbcInsertBolt插件用HikariCP,但bolt不能处理所以的业务场景所以简单写了个工具类
上代码:
/ Created by scx on 2016/9/29. / public class JdbcUtil { // 饿汉单列Mysql连接信息 public static final ConnectionProvider connectionProviderMySql = getConnectionProviderMySql(); // 饿汉单列SqlServer连接信息 public static final ConnectionProvider connectionProviderSqlServer = getConnectionProviderSqlServer(); private static Integer queryTimeoutSecs=30; private JdbcUtil(){} / 提供个设置超时的接口 @param queryTimeoutSecs / public void setQueryTimeoutSecs(Integer queryTimeoutSecs){ this.queryTimeoutSecs=queryTimeoutSecs; } /** 获取Mysql的连接信息 @param / private static ConnectionProvider getConnectionProviderMySql() { Map hikariConfigMap = Maps.newHashMap(); hikariConfigMap.put("dataSourceClassName", "com.mysql.jdbc.jdbc2.optional.MysqlDataSource"); hikariConfigMap.put("dataSource.url", "jdbc:mysql://10.100.27.67/logs"); hikariConfigMap.put("dataSource.user", "root"); hikariConfigMap.put("dataSource.password", "root"); return new HikariCPConnectionProvider(hikariConfigMap); } / 获取SqlServer的连接信息 @param */ private static ConnectionProvider getConnectionProviderSqlServer() { Map hikariConfigMap = Maps.newHashMap(); hikariConfigMap.put("dataSourceClassName", "com.microsoft.sqlserver.jdbc.SQLServerDataSource"); hikariConfigMap.put("dataSource.url", "jdbc:sqlserver://10.100.27.67:1433;DatabaseName=logs"); hikariConfigMap.put("dataSource.user", "sa"); hikariConfigMap.put("dataSource.password", "songchun110xi"); return new HikariCPConnectionProvider(hikariConfigMap); } / 单例一个mysql的Jdbc连接的客户端,用内部类实现单列可以实现调用时加载该类,且线程安全,且高效 此处已经用了HikariCP超牛连接池实例jdbc客户端 @param / private static class InitJdbcClientMySql{ private static final transient JdbcClient jdbcClientMySql = new JdbcClient(connectionProviderMySql,queryTimeoutSecs); } / 单例一个sqlServer的Jdbc连接的客户端,用内部类实现单列可以实现调用时加载该类,且线程安全,且高效 此处已经用了HikariCP超牛连接池实例jdbc客户端 @param / private static class InitJdbcClientSqlServer{ private static final transient JdbcClient jdbcClientSqlServer = new JdbcClient(connectionProviderSqlServer,queryTimeoutSecs); } / 外部调用插入mysql的方法 @param tableName @param columnLists / public static void insertMysqlByTableName(String tableName,List
}
日志实时处理代码架构结构
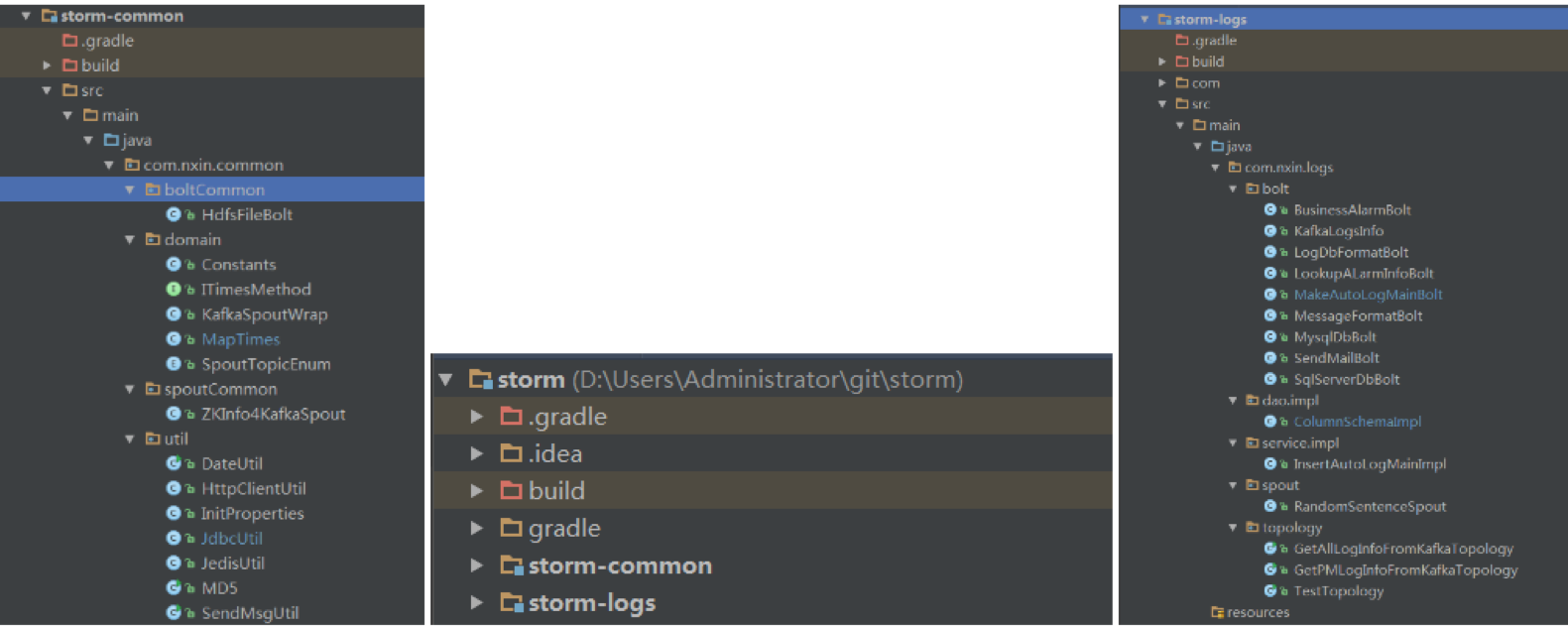
分storm-common和storm-logs,common主要放公共的bolt,spout和一些工具类。logs下主要放关于日志处理的业务bolt和spout。
我是这样考虑的,其它流处理的业务场景也可以使用storm,比如消息处理中心啥的,只要建自己的Module,不同业务发版只发自己的jar到storm集群就可以了。自己玩自己互不影响。
改公共的common后发版到storm集群的/lib下就好了,不用像web那样打一个war包。把common看成依赖的jar包就好了。
入库关系结构表